Kernel Model
In the linear-in-parameter model,
basis functions are fixed to, e.g., polynomial functions or sinusoidal functions without regard to training samples
$\{(x_i, y_i)\}_{i=1}^n$. Whereas the kernel model is introduced, which uses training input samples $\{x_i\}_{i=1}^n$ for basis function design
Let us consider a bivariate function called the kernel function $K(\cdot,\cdot)$.
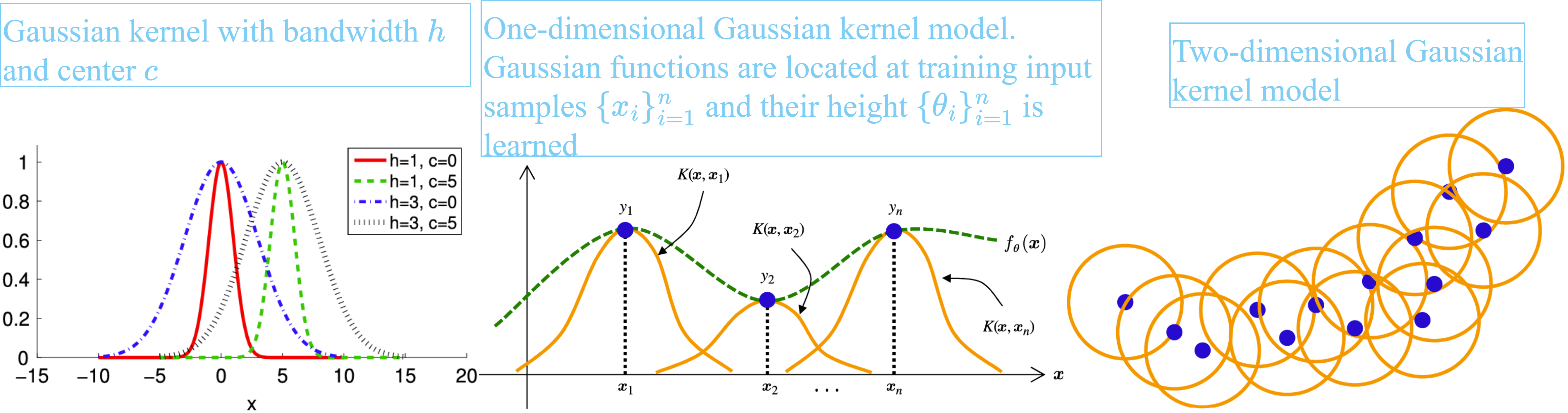
The kernel model is defined as the linear combination of $\{K(x, x_j)\}_{j=1}^n$
\[
f_\theta(x) = \sum_{j=1}^{n} \theta_j K(x, x_j)
\]
As a kernel function, the Gaussian kernel would be the most popular choice
\[
K(x, c) = \exp \left( -\frac{\|x - c\|^2}{2h^2} \right),
\]
where $\|\cdot\|$ denotes the $\ell_2$-norm
\[
\|x\| = \sqrt{x^\top x}.
\]
$h$ and $c$ are, respectively, called the Gaussian bandwidth and the Gaussian center
1Masashi Sugiyama (2016). Introduction to Statistical Machine Learning.